
OLTP sistemlerin çoklu veri merkezinden hizmet vermesi ile offline veya geriden gelebilecek/asenkron sistemlerin çoklu veri merkezinden çalıştırılması çok farklı teknolojiler ve altyapı tasarımı gerektirir.
Yaşanan kesintiler üzerine; birçok yerde önemli toplantılar gerçekleştirdik. Sıcak gündem olan “Disaster Recovery” konusunda bazı proje tecrübelerimi paylaşmak istiyorum:
2019-2020 senesinde çok önemli bir kurumda uygulama sunucularını uçtan uca upgrade etmiştik ve olmayan uygulama sunucuları DR katmanını Aktif-Aktif kurup devreye almıştık.
Arkada engineered/bütünleşik sistem veri tabanı Active-Standby şeklinde konumlandırılmış; standby Veritabanı read-only olarak replike oluyor ve veri merkezleri arasında ~70km mesafe bulunuyor(du).
Yaptığımız ölçümlemelerde ve performans testlerinde; çapraz DB erişimlerinde bir network latency olmadığından dolayı; uygulama sunucuları katmanını ACTIVE-ACTIVE devreye aldık ve bizim için bir ilk idi. Aktif-Aktif çalıştırmak ise tamamen kendi kararım ve inisiyatifim ile olmuştu; çünkü kararın devamında konfigürasyonu/kurulumları da yapmak durumundaydım.
Çoklu DR sunucuları gerçek manada çalıştırırken aşağıdaki durumları tecrübe ettim;
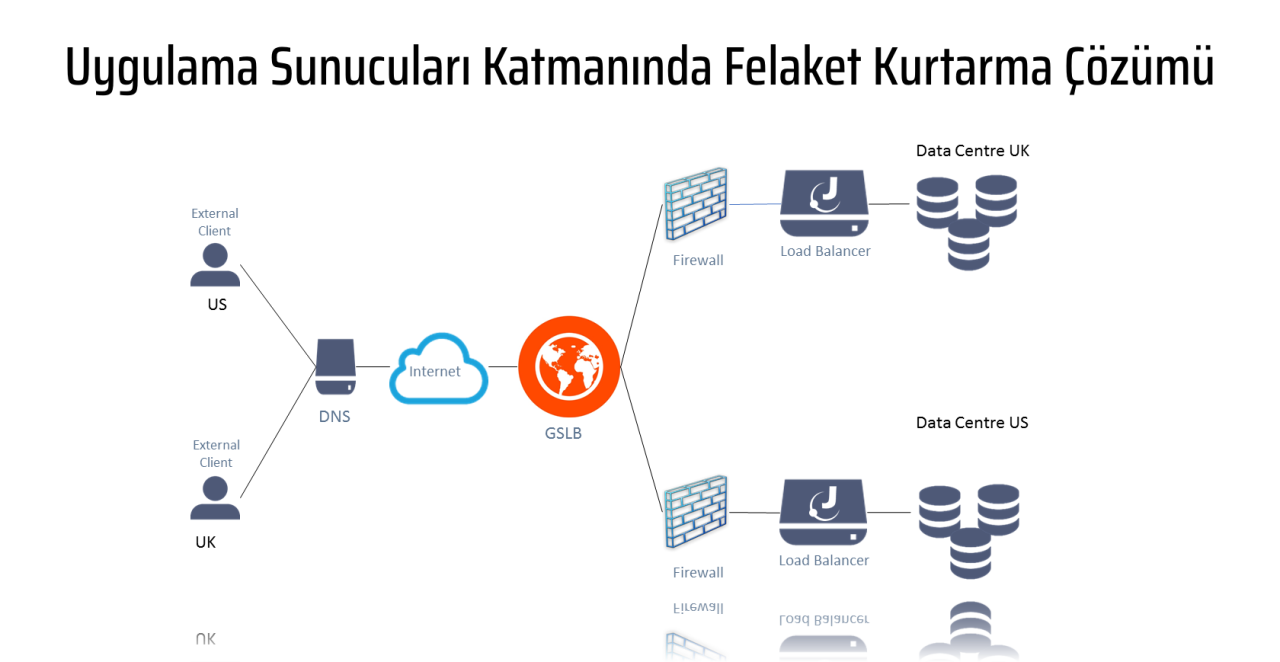
- Network katmanında GSLB kullanılmalıdır (Birçok firmada LB çözümlerinin bu özelliğinin olduğunun farkında değil; tipik bir DNS query)
- GSLB planlarken bunun birkaç yöntemi var. Multiple DNS query ile VIP health check kontrolü ile çoklu datacenter trafik dağıtımı
- Büyük çaplı uygulamaları IP’den bağımsız çalıştırmak bir hayli zordur; yüzde %99.99 geniş çaplı CRM, internet şube… vb. on-premise uygulamalar lokal host/IP, DB konfigürasyonu ile çalışır (Bunu tartışmaya gerek yok, büyük oranda bu şekilde). Uygulamaların IP’den bağımsız çalışmalarını ve DNS/hosts kayıtları ile çalışmasını sağladık; kodlarda gerekli düzenlemeleri tespit edip yaptırdık. Bu sayede çapraz trafiklerin önüne geçmiş olduk.
- Uygulamalar aynı IP ile sanal ortamda kaldırıldığında dahi aynı yapı birebir DR ortamında da oluşturulmalıdır, ki bütün entegrasyonlar ve erişimler sağlıklı çalışabilsin. Ayrıca felaket anında trafik yönlendirme bir butona basmak kadar ON/OFF kolay olabilmeli. Felaket anından önce son kullanıcılara açık kritik sistemlerin çoklu NameServer DNS zone’ları, çoklu IP kayıtları, failover IP kayıtları.. vs. olmalıdır. Felaket anında DNS güncelleyerek uygulamaları ayağa kaldırmaya çalışmak oldukça zor ve eğer olası bir tatbikat yapılmamış, mevcutta takip edilmesi gereken bir prosedür bulunmuyorsa tekrar çalıştırılması günler sürebilir.
- DR ortamları ayağa kaldırırken Multicast/Unicast konfigürasyonlardan tutun, bütün uygulama sunucusu cache ve cluster altyapısına kadar mevcut klon ayarları ile çalışması neredeyse imkansız oluyor. Kullanılan teknolojiler için tek tek tespit yapılmalı ve ilgili teknolojiyi multiple region DC (çoklu veri merkezi) destekleyen çözümü ile konfigüre edip öylece devreye almak gerekiyor. Örneğin JMS, JTA, Multicast Cache, Federation service, Session Replication… vb.
- Java için bir örnek vermek gerekiyorsa; uygulamanın veritabanı bağlantı URL’i JNDI üzerinden ve DNS host kaydı ile sağlanmalıdır; ayrıca ilgili uygulama sunucusunda Fail-Over veri kaynağı tanımları planlanmalı ve hızlıca devreye alınabilecek şekilde kurulum sağlanmalıdır.
- OLTP sistemlerde veri merkezleri arasında mesafe çok fazla ise (Ör. İstanbul – Ankara) bu durumda veri tabanı replikasyonları arasında çapraz uygulama sunucuları veri tabanı erişimlerinde uygulamanın performanslı bir şekilde gecikme olmaksızın çalışması mümkün değildir. Aktif-Aktif olarak yine çözümler üretilebilir fakat bu aşamada yazılım geliştirme ve trafik yönetimi birlikte tasarlanmalıdır. Burada Aktif-Pasif yöntem tercih edilmelidir. Pasif sistemler için uygulama sunucuları sürekli hazır olmalıdır. Olası bir felakette idari karar alınarak 3-5 dakikalık bir kesinti ile (1 saat dahi iyi bir zaman) trafik yedek veri merkezine yönlendirile bilinmelidir. Uygulama güncellemeleri ve deployment’lar için CI/CD replikasyon çözümü ile DR ortamlarda sürekli güncel tutulmalı ve düzenli olarak DR tatbikatları yapılmalıdır. Uygulama sunucularını bu şekilde planlamak mümkün ama büyük oranda bu kısım atlanıyor.
Toparlayacak olursak, veri tabanı sistemlerinin veya file sunucuların DR altyapısını oluşturmak işin en kolay kısmıdır; zaten sadece bunu yapan firmalar bizim DR ortamımız var diyerek işin içinden sıyrılıyor. Ama gerçek felaket anlarında bu ilave veri merkezi üzerinden trafiği anlık yönlendirmeye gelince orda FAIL ediyor her şey. Zaten bu kısım çok zor olduğu için ve ciddi proje kaynağı, know-how ve yatırım gerektirdiği için birçoğumuz “çıplak kralı” şık kıyafeti ile görmeyi tercih ediyor.

